1
La recherche, un enfer administratif
C’est désormais un lieu commun de la recherche en France, et la première recommandation du rapport de l’Académie des sciences sur les structures de la recherche publique française en septembre 2012 : il faut simplifier (et les académiciens ajoutent même « arrêter de compliquer ») les procédures administratives. Explications (nous soulignons) :
La facilité de diffusion par voie électronique de questionnaires construits de manière peu rationnelle par des personnes très éloignées des laboratoires et n’ayant pas une connaissance réelle de la vie des laboratoires amène les chercheurs à passer un temps de plus en plus grand à remplir de trop nombreux formulaires qui nourrissent des « cimetières à informations » dont la taille semble seulement limitée par celle des serveurs qui hébergent ces formulaires une fois remplis. Les chercheurs ne sont pas au service des différentes structures administratives, mais au contraire, ces structures doivent contribuer à faciliter la vie des créateurs et des innovateurs. Faire simple au lieu de faire compliqué doit être le principe de base à respecter lors de la mise en place de toutes les modifications qui devront être apportées aux structures de la recherche publique en France. Par ailleurs, la mise en place de ces simplifications doit se faire en s’appuyant sur des avis de scientifiques compétents et des indicateurs simples, efficaces et validés.
La préoccupation des académiciens est également financière : « Dans une période de contraintes budgétaires, nous tenons à souligner que nos propositions de simplification et d’arrêt de la complication des procédures administratives sont une excellente manière de redéployer, à volume constant, des moyens financiers vers les laboratoires et les équipes de recherche ». C’est une motivation qui s’ajoute au triste constat de tant de temps gâché pour si peu de résultat ! À la clé, même pas un « Gateway to Research« à la française, comme nous le regrettions au chapitre précédent…
Le cycle de vie de la recherche
Pour comprendre ce qui pourrait être amélioré dans l’administration de la recherche, il faut partir du cycle de vie (théorique) de la recherche et commencer à le décomposer en logiciels, systèmes d’information et bases de données… Un travail titanesque ! À défaut de tout couvrir, nous saurons exactement d’où vient ce sentiment de gâchis même quand des efforts sont faits pour fluidifier la circulation des informations.
Le cycle de vie de la recherche, c’est cette circulation des connaissances d’un document à l’autre, passant du stade de questions de recherche dans une demande de financement à celui de résultats publiés dans un article scientifique, faisant naître de nouvelles hypothèses à tester dans de nouveaux projets, générant des données venant nourrir d’autres projets, etc. (voir schéma ci-après).

Ce cycle devrait être fluide, et pourrait l’être si (par exemple) chaque information saisie était réutilisée plusieurs fois dans plusieurs contextes : « input once, output many« . Or en pratique, chaque étape est gérée dans un système d’information spécifique : les publications sont gérées dans des outils de gestion bibliographique et stockées dans des archives ouvertes, les données de la recherche alimentent des bases de données spécialisées ou prennent la poussière sur un disque dur, chaque agence de financement a sa propre plateforme de soumission des projets de recherche, les sites web de laboratoire ne se mettent pas à jour automatiquement, etc. Ceci suppose de développer l’interopérabilité des systèmes avec des normes et des formats standards.
Un gros chantier, nous ne le nions pas. Mais pas nouveau : l’interopérabilité s’impose aux établissements de recherche depuis le décret du 2 mars 2007, dans ses trois dimensions :
- interopérabilité organisationnelle qui concerne les échanges automatisés d’informations entre organisations d’un même secteur ;
- interopérabilité sémantique qui définit un langage commun à base de normes et de référentiels permettant à différentes applications d’interpréter de façon homogène les données transmises pour les réutiliser sans erreur ou perte d’information ;
- interopérabilité technique qui couvre la mise en relation des systèmes par des interfaces ouvertes, l’interconnexion des services…
Voici la théorie. Pour vous donner une idée de la situation réelle, attardons nous sur le travail multilatéral entrepris par la Bibliothèque scientifique numérique (BSN), une plateforme de coopération pour le développement et l’usage de la documentation scientifique numérique, lancée dans le cadre du plan Besson pour le développement de l’économique numérique, et de la Stratégie nationale de recherche et d’innovation (SNRI). Au sein du groupe de travail n° 3 de la BSN (BSN3), intitulé « Dispositifs de signalement », est conduit le projet Conditor visant à « recenser l’ensemble de la production scientifique de la communauté Enseignement Supérieur et Recherche ». Vaste programme ! Faisant le constat d’un éparpillement indéniable entre « différents référentiels de structures, dictionnaires d’affiliations, auteurs, personnel, revues, colloques, thématiques… [qui] existent au niveau national, institutionnel, local : le besoin de référentiels communs (ou liés entre eux) est exprimé par tous ». Mais si le besoin d’interopérabilité est évident, les moyens d’y parvenir ne le sont pas et Conditor démarre sous la forme d’une expérimentation réunissant l’Agence bibliographique de l’enseignement supérieur (Abes), les directions du CNRS chargées de l’appui à la structuration territoriale de la recherche (CNRS-DASTR), de l’information scientfiique et technique (CNRS-DIST) et des SHS (CNRS-INSHS), l’Institut national de l’information scientifique et technique (Inist), le Centre pour la communication scientifique directe (CCSD), les instituts de recherche agronomique (Inra) et pour le développement (IRD), Inria, le Ministère de l’enseignement supérieur et de la recherche, l’université Paris Dauphine, et l’université de Bordeaux. Tout ça pour traiter uniquement de l’aval du cycle de vie de la recherche ! Parce qu’un schéma vaut mieux qu’on long discours, la figure suivante illustre à quoi Conditor doit aboutir.

Autre exemple : les chercheurs qui déposent leurs publications dans l’archive ouverte peuvent ensuite exporter leur production dans un format directement compatible avec les rapports d’activité du CNRS (CRAC en sciences formelles et expérimentales, RIBAC en sciences humaines et sociales). L’application IdRef développée par l’Abes se base sur les métadonnées saisies dans HAL pour créer un référentiel d’auteurs, enrichi et contrôlé par des documentalistes, et s’interfaçant avec les annuaires de chercheurs existant dans les établissements. Mais — car il y a un mais — les compléments de saisie à chaque acte de gestion ne sont jamais exploités : ainsi, HAL nourrit les rapports CRAC ou RIBAC mais toutes les autres informations que les chercheurs ou les administrateurs y auront mis ne reviendront jamais dans HAL. D’où des saisies multiples, et un sentiment de gâchis même quand des efforts sont faits pour faciliter l’échange d’informations.
Nous voilà donc éclairés sur la situation française, et la lourde tâche consistant à fluidifier la circulation des informations. En Grande-Bretagne, ceux qui ont abordé le problème ont identifié « CERIF as the best option for improving interoperability and exchange of research information« . Qu’est-ce que CERIF ? C’est un des secrets derrière le portail « Gateway to Research« , que nous allons dévoiler maintenant.
Petit détour par l’international
Le Royaume-Uni possède avec « Gateway to Research » un portail fabuleux d’accès aux projets de recherche, aux chercheurs et aux laboratoires. Qu’ont-ils fait de plus que la France ? Répondre à cette question va nécessiter de pénétrer dans la mécanique des formats et standards d’échanges de données entre les laboratoires de recherche et leurs financeurs.
Reprenons notre cycle de vie de la recherche : on s’aperçoit que la gauche du cycle concerne les recherches menées au laboratoire, tandis que la partie droite concerne les agences de financement (voir schéma ci-après). Or c’est précisément sur l’optimisation des relations entre la partie gauche et la partie droite, lorsqu’organismes de recherche et agences de financement s’échangent des informations cruciales, que s’appuie le portail « Gateway to Research ».

Au commencement, cinq des huit agences de financement de la recherche britanniques (RCUK) ont mis en place en novembre 2011 le système d’information ROS (« Research Outcomes System ») pour mutualiser la saisie des informations concernant la production des recherches financées, selon neufs catégories :
- publications
- collaborations / partenariats
- co-financements obtenus
- développement des compétences du personnel
- dissémination / communication
- propriété intellectuelle et valorisation
- distinctions et récompenses
- impact
- autres produits de la recherche
Ainsi, au lieu de maintenir cinq systèmes distincts et imparfaits, ces agences de financement ont préféré mutualiser leurs efforts pour installer un système unique, fiable et dessinant un paysage plus complet de la recherche britannique… qui alimente directement « Gateway to Research » !
En pratique, ROS peut être renseigné de trois manières différentes au moment de rendre compte de l’avancement d’une recherche (voir schéma ci-après) :
- les chercheurs peuvent saisir manuellement leurs données via les formulaires en ligne de ROS, ce qui peut vite s’avérer chronophage
- les administrateurs ont aussi la possibilité de soumettre des données par lot sous forme d’un fichier Excel, qu’ils auront exporté depuis leur système d’information interne — ce qui suppose que les champs soient bien alignés entre la sortie de ce dernier et l’entrée de ROS
- une troisième solution plus automatisée a été mise en place : l’utilisation d’un format XML interopérable, suivant le schéma de données CERIF (Common European Research Information Format).

Le fameux format CERIF apparaît enfin ! Les raisons d’utiliser CERIF sont nombreuses, comme nous allons le voir, et les responsables de ROS en donnent plusieurs justifications. Nous pouvons par exemple citer celle-ci (nous soulignons) :
We hope that utilising the CERIF- XML schema (…) to deliver tight data specification and set up automated data export and import routines will help save public money as the administrative costs of delivering the information will be reduced. Having clearer definitions will also reduce the potential for confusion and anxiety within the academic community and for administrators interacting with the ROS system.
CERIF représente donc un gain financier et humain évident. Au-delà même de son utilisation dans le système ROS, un projet britannique vise à déterminer dans quelle mesure CERIF pourrait servir de base à une infrastructure nationale pour le reporting de la recherche. Attention : « infrastructure nationale » ne veut pas dire système centralisé unique (qui peut en effrayer certains). L’existence des systèmes ROS ou autre ResearchFish n’est pas menacée, l’objectif étant de créer des passerelles entre les différents outils et plateformes — bref, de l’interopérabilité !
Or CERIF se prête merveilleusement bien à cette ambition d’interopérabilité des informations sur la recherche, à laquelle « Gateway to Research » doit tant. Pour deux raisons principales : parce qu’il est fait pour ça et parce qu’il est historiquement européen donc international. Nous allons détailler ces raisons dans la section suivante, assez technique, que les plus pressés peuvent sauter. Nous montrerons ensuite que CERIF fonctionne déjà dans de nombreuses autres situations concrètes.
CERIF, un cadre de référence pour l’identification des activités de la recherche
CERIF, ou « Common European Research Information Format », est un schéma conceptuel de données décrivant le domaine de la recherche sous la forme d’un modèle entité-association. À partir de ce modèle peuvent être générés des scripts SQL pour plusieurs langages de bases de données (Oracle, mySQL, DB2…). Les entités présentes dans le modèle concernent les personnes, les organisations, les projets, les publications, les brevets, les données, les équipements, les infrastructures, les financements, les indicateurs… Voici par exemple quelques unes des entités présentes dans le modèle et leurs relations :

La structure du modèle CERIF a directement inspiré le format d’échange CERIF-XML, qui est une adaptation au langage XML d’un modèle entité-association. En ce qui concerne le web sémantique, il n’existe aucune ontologie formelle CERIF en OWL ou RDF. Des efforts ont été faits pour exprimer CERIF dans VIVO et vont être poursuivis. Néanmoins, les auteurs de CERIF insistent sur le fait que la sémantique est déjà présente dans CERIF, s’appuyant sur certains vocabulaires contrôlés, et que les ontologies du Linked Data ne feraient que la réexposer en RDF.
Par ailleurs, comme l’indique le « E » de CERIF, ce modèle est historiquement européen. Aujourd’hui fort du statut de recommandation aux États membres de l’UE pour l’harmonisation, CERIF a fait ses premiers pas en 1987 avec un séminaire et un groupe de travail lancés par l’Union européenne. En 1991, la première version de CERIF ne couvrait que les projets, remplacée en 2000 par un modèle de données complet avec métadonnées et modèle d’échange. En 2002, le développement de CERIF a été confié par la Commission européenne à l’association euroCRIS basée aux Pays-Bas. Depuis lors, les évolutions de CERIF ont permis d’introduire une couche sémantique en 2008 et le format d’échange CERIF-XML en 2012.
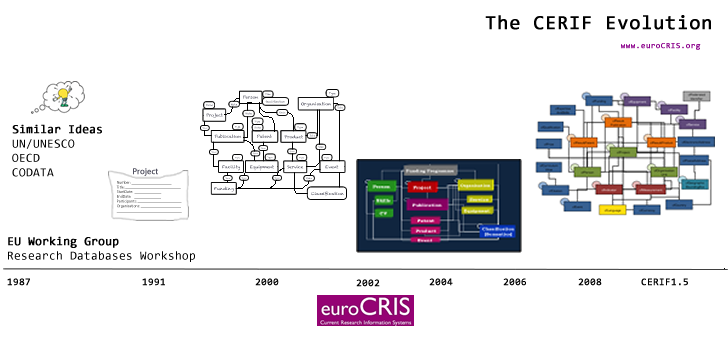
Notons enfin qu’euroCRIS se bat comme un beau diable pour faire reconnaître le format CERIF, en étant impliqué dans 3 projets européens : EuroRIs-Net+, OpenAIREPlus et ENGAGE. Malheureusement, le manque de financement européen pour CERIF est vécu douloureusement par euroCRIS, qui voit les États-Unis soutenir largement leur solution VIVO (dont on reparlera dans le troisième et dernier chapitre de notre enquête).
Mais s’il y a un pays qui a embrassé largement CERIF, c’est bien la Grande-Bretagne, avec plus de 2 millions de livres dépensées sur le terrain pour tester des scénarios d’usage, encourager l’adoption du format CERIF et développer ses fonctionnalités. Lors des réunions d’euroCRIS, les autres pays montrent régulièrement une certaine jalousie envers cette implication très forte de la Grande-Bretagne dans CERIF.
Résultat : CERIF est devenu le standard à adopter par l’ensemble de la communauté scientifique britannique pour « fluidifier la circulation des données entre parties prenantes, améliorer la qualité des données et réduire les coûts en permettant des procédures d’échange de données plus efficaces ». Une fois cette recommandation importante émise, les travaux ont continué pour tester des scénarios d’usage (transfert de données à l’occasion de la mutation d’un chercheur, fonctions d’import/export entre les bases de données) et s’accorder sur un schéma CERIF-XML standard qui satisfasse au contexte britannique tout en restant simple d’emploi. La figure ci-après illustre par exemple les bénéfices attendus du projet « CERIF in Action », par famille d’acteurs.

CERIF est donc un schéma de données standard, important pour rationaliser la circulation des informations de recherche. Mais un schéma de données n’est rien s’il n’est pas utilisé au moment où les données sont produites. D’où l’importance des logiciels CRIS basés sur CERIF et utilisés au laboratoire et dans les organismes de recherche pour saisir les informations liées aux nouvelles publications, aux nouveaux financements et projets, aux nouveaux personnels…
Des CRIS pour gérer les informations au laboratoire
À ce stade le schéma de données CERIF est encore abstrait, un peu comme si on essayait de vendre la révolution bureautique en vantant les mérites du format de fichier DOC. Rentrons donc dans le cœur du sujet en s’intéressant aux CRIS, qui sont aux informations de recherche ce que les logiciels de traitement de texte sont à la bureautique. Les CRIS forment la famille des Current Research Information Systems, ou systèmes d’information sur la recherche en cours : ce sont des logiciels qui permettent de gérer les informations de recherche au laboratoire (personnels, projets, financements, publications…).
L’association euroCRIS gère un répertoire des logiciels CRIS déployés dans le monde, qui fait apparaître une forte variabilité : certains CRIS sont basés sur le modèle de données CERIF, d’autres ont leur propre modèle de données mais peuvent exporter au format CERIF-XML afin d’être compris par d’autres CRIS compatibles avec CERIF ; certains CRIS sont des logiciels commerciaux, d’autres sont des logiciels développés en interne à une université ; certains sont spécifiques à un pays, d’autres sont utilisés à travers le monde…
S’il fallait n’en retenir que quelques uns, ce seraient les trois logiciels commerciaux les plus utilisés :
- Pure, développé par la société Atira et racheté par Elsevier en août 2012, est un logiciel complet qui a poussé très loin dans ses dernières versions les fonctionnalités d’analyse qualitative des projets et de métrique de la recherche ;
- Converis, développé par la société Avedas et racheté par Thomson Reuters en décembre 2013, est une solution modulaire qui couvre la gestion des demandes de financement, la gestion des publications et/ou la gestion des doctorants (voir vidéo ci-après) ;
- Elements, développé par la société Symplectic, est centré sur la gestion des publications par les chercheurs eux mêmes, rendue très intuitive et automatisée : le logiciel envoie des alertes à chaque nouvelle publication détectée dans des bases de données comme Web of Science.
Ces logiciels font leur trou : on dénombre entre 150 et 200 installations de CRIS en Europe, et la Grande-Bretagne est passée de 0 à 51 installations entre mai 2009 et mars 2012, soit un taux d’adoption de 30% sur l’ensemble de ses établissements d’enseignement supérieur et de recherche. Certains pays ont fait le choix de solutions nationales, comme le programme CRIStin en Norvège et METIS aux Pays-Bas. Enfin, en janvier 2013, dans son rapport sur la standardisation des remontées d’information sur la recherche, le Wissenschaftsrat allemand (équivalent de notre Conseil stratégique de la recherche) a recommandé fortement que les nouveaux CRIS utilisés dans le pays soient compatibles CERIF.
Cette tendance n’est pas étonnante selon une étude britannique évaluant l’économie de ce secteur. Elle a chiffré que le déploiement de logiciels CRIS compatibles CERIF ferait économiser 177 000 livres (environ 215 000 euros) par an et par établissement, soit 25 à 30 % des dépenses annuelles liées au dépôt et à la gestion des bourses de recherche. Un système d’échange de données CERIF entre les établissements de recherche et les financeurs ferait économiser, lui, 94,5 millions de livres (environ 115 millions d’euros) par an au secteur ! Quant aux coûts lié au déploiement d’un logiciel CRIS, les retours d’expérience obtenus par cette étude convergent vers une dépense annuelle de 12 à 25 000 € par établissement.
Les logiciels CRIS compatibles avec le standard CERIF sont donc les briques d’un système d’information moderne, interopérable à l’échelle d’un pays et bientôt entre les pays. Et cerise sur le gâteau, ce sont des logiciels ergonomiques et conviviaux qu’on aimerait avoir dans son laboratoire ou son université !
Ce que nous apprend le cas britannique
En conclusion, on voit bien que le portail britannique « Gateway to Research » n’est pas une réussite miraculeuse mais le résultat d’une mutualisation d’une part (les RCUK se rassemblant pour créer le système de reporting ROS), et d’un travail d’interopérabilité d’autre part : les données du ROS utilisent le format CERIF, qui sert de base aux logiciels CRIS utilisés dans les organismes de recherche. Qui plus est, ces logiciels CRIS utilisés dans différents établissements leur permettent d’échanger des données, par exemple à l’occasion de la mutation d’un chercheur ou du changement de tutelle d’un laboratoire (voir schéma ci-après). Une feuille de route toute tracée pour la France… qui semble malheureusement encore loin !

En France, des envies mais peu d’avancées
Pour cette dernière partie, et maintenant que nous avons compris ce qu’il était possible de faire avec les technologies disponibles en 2014, nous allons décortiquer le cas de la France. Quels CRIS utilise-t-elle ? A-t-elle dans les tuyaux des projets utilisant le potentiel de CERIF ?
Commençons par constater que la France ne peut pas feindre d’ignorer cette dynamique internationale, avec 5 Français membres de l’association euroCRIS. Mais que pèsent 5 représentants face aux 44 membres britanniques ? Alors que les études économiques sont si édifiantes, la France continue à utiliser des logiciels vieillissants ou en décalage avec cette vague de fond : Cocktail, Pléiade et GRAAL.
La suite Cocktail se définit comme un progiciel de gestion intégrée (PGI) libre pour l’enseignement supérieur et la recherche. L’un de ses modules, SANGRIA, est consacré à la gestion administrative et financière de la recherche à travers la gestion des structures (personnels, dotations financières, évaluations…) et des projets (réponses aux appels d’offres, partenariats…). Cocktail, né à l’IUT de la Rochelle en 1993, est intrinsèquement lié à la communauté universitaire française. À partir de 1997, il a commencé à être mutualisé entre les établissements intéressés, pour conduire en 2005 au consortium Cocktail chargé de définir les règles de mutualisation pour le développement des briques logicielles qui équipent aujourd’hui plus de 70 universités (sur 83) pour la gestion de leurs personnels, leurs salles, leur comptabilité… Mais ce n’est qu’en 2011 que Cocktail a développé avec SANGRIA une solution spécifique à la recherche. À titre d’exemple, les travaux menés dans le cadre de SANGRIA ont permis de développer un glossaire des termes (« unité », « fédération », « tutelle », « dotation »…) utilisés pour en limiter les différentes interprétations possibles et cadrer l’utilisation de l’application.
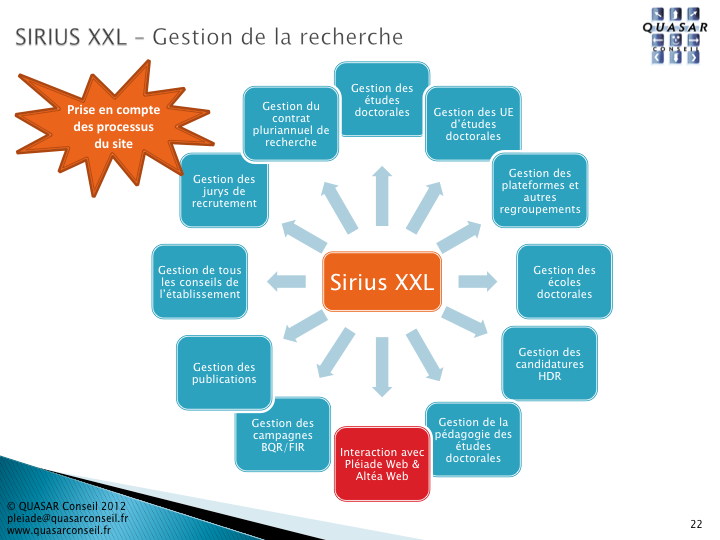
Pléiade est un autre PGI mais commercial, édité par la société QUASAR Conseil, qui intègre le module Sirius XXL consacré à la gestion de la recherche. Celui-ci offre par exemple la possibilité d’importer une liste de publications depuis l’archive ouverte HAL pour les affecter à la production des chercheurs selon une codification conforme à celle de l’AERES. Il permet également de gérer, par contrat pluriannuel de recherche, toutes les données relatives au laboratoire, ses équipes, personnels et doctorants, ainsi que ses activités (publications, contrats de recherche, dossiers de propriété intellectuelle, prospection…). Il exporte ainsi certaines informations et tableaux exigés par l’AERES ou le ministère.
Enfin, GRAAL (Gestion des données de la Recherche, Application des Activités Laboratoires) est un logiciel lancé en 2000 par le Centre interuniversitaire de calcul de Grenoble puis élargi en 2004 aux quatre universités de l’académie de Grenoble, à l’université Blaise Pascal de Clermont-Ferrand et à l’université Louis Pasteur de Strasbourg. Son pilotage a alors été confié à un Groupement d’intérêt scientifique (GIS) rassemblant les partenaires publics intéressés. Fin 2009, GRAAL était déployé dans une cinquantaine d’établissements. Comme les logiciels précédents, GRAAL est une application qui vise à présenter de manière cohérente les unités de recherche au sein de l’université, incluant les personnels et leurs activités scientifiques (publications, brevets, manifestations, équipements…), ainsi que le suivi des moyens financiers (dotations du contrat quadriennal et sur appels d’offres) et des activités internationales (conventions de partenariat, congrès…). Comme SANGRIA, il permet d’historiciser les données et donc de suivre et gérer les transformations des unités de recherche, des moyens financiers et humains, et des indicateurs. Il permet à trois niveaux hiérarchiques dans l’établissement de saisir ou accéder à certaines données : l’unité de recherche, la direction de la recherche et la présidence (voir schéma ci-après).

Deux types d’interopérabilité existent dans GRAAL : avec SIREDO (utilisé par le Ministère dans le cadre de la gestion des contrats quadriennaux) et avec l’archive ouverte HAL. Avec HAL, l’interopérabilité existe dans les deux sens, c’est-à-dire que les métadonnées des publications peuvent être saisies dans GRAAL et attachées au fichier de l’article, l’ensemble étant ensuite versé automatiquement dans GRAAL. À l’inverse, les notices présentes dans HAL peuvent être moissonnées par GRAAL afin d’alimenter le reporting.
Mais patatras : alors que ce logiciel était bien parti pour s’imposer dans le paysage, soutenu dans son comité de pilotage par le ministère, la Conférence des présidents d’universités (CPU) et l’Agence de mutualisation des universités et des établissements (AMUE), cette dernière a annoncé en 2010 qu’elle retirait son soutien à GRAAL. Pour Michelle Gillet de la société concurrente QUASAR Conseil, GRAAL n’était plus à la hauteur des nouveaux enjeux de la gestion de la recherche, illustrés par le niveau d’exigence des documents à fournir à l’AERES pour la vague 2012-2015. Mais l’AMUE avait un plan B : s’allier avec le CNRS et la CPU pour développer une solution remplaçant GRAAL, à savoir CAPLAB (Cartographie, Activités et Pilotage du LABoratoire). Inutile de refaire le topo, résumé par le schéma ci-après :

Et alors qu’aucun des logiciels précédents ne respectait le format de données standard CERIF, l’AMUE donne des signes de bonne volonté en adhérant fin 2012 à l’association EuroCRIS ! Mais il y a un os : pour l’instant CAPLAB n’est qu’une coquille vide, un projet sans logiciel. Pourtant, le calendrier annoncé en 2012 était sans ambiguité (voir capture ci-après) : après rédaction du cahier des charges, un appel d’offres aurait dû être lancé en 2012 pour concevoir et réaliser l’outil en 2013. Nous sommes en 2015 et l’appel d’offres n’a toujours pas été lancé ! Renseignements pris en février 2013 auprès de l’AMUE, un premier benchmark avec tous les outils du marché a permis de restreindre le choix à 3 solutions mais seul un appel d’offres compétitif peut permettre maintenant de sélectionner l’un de ces trois prestataires.

Alors pourquoi tarde-t-il autant à venir ? L’explication de ce retard a été fournie par l’Inspection générale de l’administration de l’éducation nationale et de la recherche (IGAENR) dans son rapport de décembre 2013 consacré à l’AMUE. On y apprend que le développement de CAPLAB a été confié à l’AMUE dans le cadre d’un accord signé avec le CNRS en décembre 2011, avant qu’apparaissent des « désaccords sur le projet de cahier des charges et sur les modalités de la consultation des éditeurs de logiciels ». Dans son rapport annuel, l’AMUE explique de son côté que « la constitution d’un appel d’offres a été finalisée en septembre 2013 » mais « le comité de pilotage stratégique recherche n’ayant pu se réunir, la décision de s’engager sur la publication de ce marché a dû être reportée ».
Les inspecteurs de l’IGAENR recommandent au Ministère de l’enseignement supérieur et de la recherche de « réaffirmer la volonté de voir les projets conjoints GESTLAB et CAPLAB aboutir rapidement », et on ne peut qu’être d’accord. Mais cela suffira-t-il ? Ces atermoiements ne peuvent plus continuer, il faut désormais avancer vite !
Car en attendant les transformations qu’ont connues des pays comme la Grande-Bretagne ou les Pays-Bas, la France en est réduite à bricoler. Prenons par exemple les nombreuses procédures d’évaluation des unités de recherche : au CNRS, l’Institut des SHS a lancé l’outil RIBAC en se fixant comme objectif de « réduire les redondances de saisie : par exemple, l’import des références des publications entrées dans l’archive ouverte HAL-SHS ». Mais les auteurs reconnaissent qu’il reste « à progresser encore pour automatiser davantage la saisie » et la rendre plus fiable, puisque deux personnes à plein temps sont employées à vérifier certaines informations manquantes, effectuer des tâches de dédoublonnage etc. Ils aimeraient également « parvenir à une sorte de document unique, qui pourrait servir à plusieurs services, organismes, ou objectifs collectifs ou individuels » : faute de document unique, RIBAC propose actuellement un export des données en formats Word et Excel, charge aux administrateurs de les bidouiller pour les faire entrer dans les cases des autres administrations. On ne s’étonnera donc pas que le rapport de Denise Pumain et Frédéric Dardel sur l’évaluation de la recherche et le passage de l’AERES au HCERES (janvier 2014) constate que « le dossier demandé aux unités pourrait progressivement être allégé, en étant pré-rempli, à partir des bases de données du ministère ou des établissements, de nombreuses informations factuelles qu’il suffirait ensuite aux directeurs d’unités de vérifier. » Rappelons que dans d’autres pays, c’est le format CERIF qui sert de monnaie d’échange entre les établissements, leurs tutelles, leurs évaluateurs et leurs financeurs. Mais de CERIF, il est nul question dans ce rapport…
De ce portrait que nous avons souhaité fidèle de la situation, chacun tirera les conclusions qu’il veut. De notre côté, le choix est fait : nous demandons plus d’effort dans l’interopérabilité des systèmes d’information de la recherche française, le déploiement de logiciels CRIS conformes aux standards internationaux, et l’accès aux données sur la recherche aujourd’hui éparpillées entre ces multiples silos… pour les exploiter à leur juste valeur !
Bonus : de l’administration de la recherche aux archives ouvertes
Pour finir sur une note positive, il faut mentionner comment ces systèmes pourraient créer des synergies vertueuses. Les chercheurs se plaignent régulièrement, en petit comité (comme dans cet échange en réunion de labo rapporté sur une liste de diffusion) ou sur les réseaux sociaux, de la saisie chronophage des informations dans HAL. Or, de son propre aveu, « [le projet] Conditor sera un facteur d’incitation au dépôt dans les archives ouvertes en limitant la saisie de méta-données ». Cela se vérifie partout dans le monde, où les logiciels CRIS font tout ce qui est techniquement possible pour faciliter le dépôt. Par exemple, les utilisateurs du logiciel Elements de Symplectic peuvent repérer dans la base de données d’articles en biomédecine PubMed (ou plus exactement son miroir européen Europe PMC) leurs publications et les charger dans leur archive institutionnelle : tous les champs connus sont pré-remplis et la licence de l’éditeur est affichée pour aider à choisir la version (preprint, postprint) qui peut légalement être déposée. Qui plus est, dès qu’un éditeur assouplit sa politique le logiciel va proposer spontanément au chercheur de déposer ses anciens articles concernés par le changement de licence (voir capture ci-après) !

Ainsi, en même temps qu’elle faciliterait l’administration de la recherche, l’adoption large de logiciels CRIS modernes pourrait faciliter l’accès libre au publications scientifiques… qu’attend-on encore pour réagir ?

{kind=link}
{kind=link}